
|
| Given an audio clip and a target video, our Emotional Video Portraits (EVP) approach is capable of generating emotion-controllable talking portraits and change the emotion of them smoothly by interpolating at the latent space.. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Given an audio clip and a target video, our Emotional Video Portraits (EVP) approach is capable of generating emotion-controllable talking portraits and change the emotion of them smoothly by interpolating at the latent space.. |
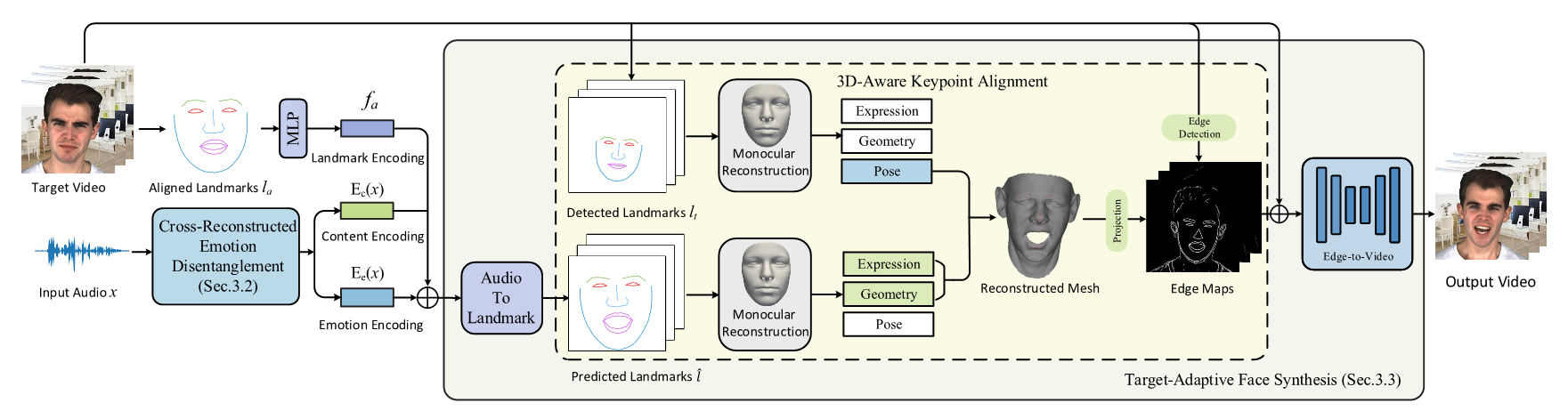
| In this work, we present Emotional Video Portraits (EVP), a system for synthesizing high-quality video portraits with vivid emotional dynamics driven by audios. Specifically, we propose the Cross-Reconstructed Emotion Disentanglement technique to decompose speech into two decoupled spaces, i.e., a duration-independent emotion space and a duration dependent content space. With the disentangled features, dynamic 2D emotional facial landmarks can be deduced. Then we propose the Target-Adaptive Face Synthesis technique to generate the final high-quality video portraits, by bridging the gap between the deduced landmarks and the natural head poses of target videos. Extensive experiments demonstrate the effectiveness of our method both qualitatively and quantitatively. |
 |
 |
Audio-Driven Emotional Video Portraits. In CVPR, 2021. (hosted on ArXiv) |
Acknowledgements |